자바
네이버 뉴스 크롤링
코드 죄수
2022. 9. 1. 21:10
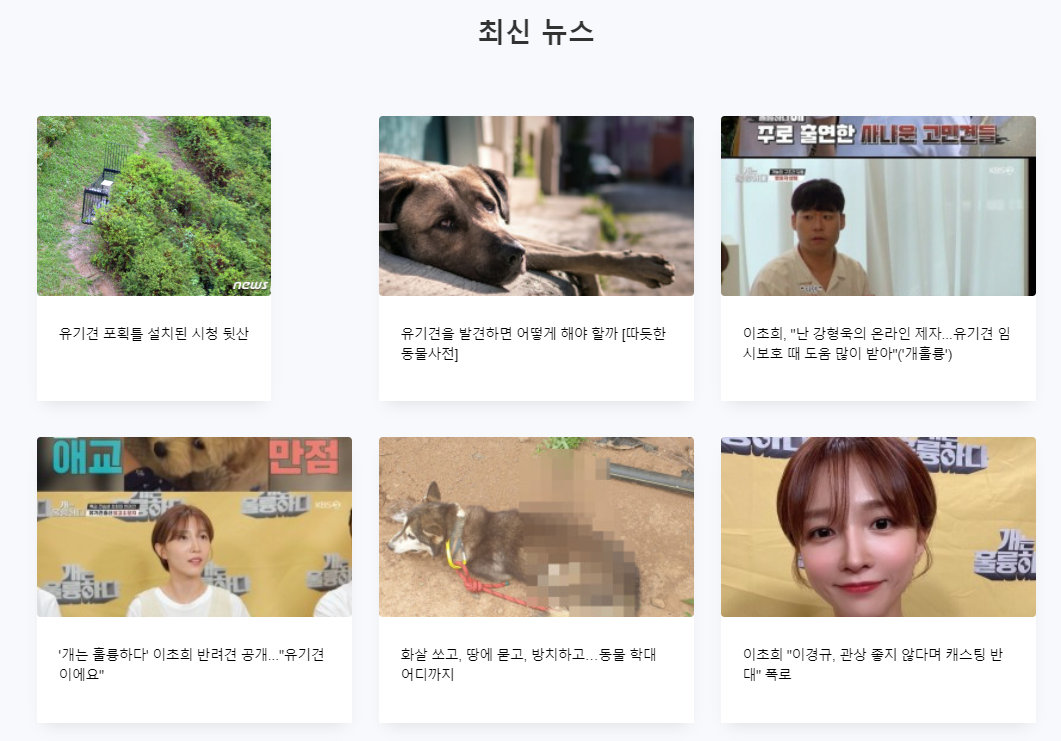
홈페이지에 유기견에 관한 네이버 뉴스를 크롤링하여 최신 6개만 띄워주는 것을 만들었다.
크롤링은 파이썬으로 뉴스를 가져와서 mysql에 저장하고
저장된 정보를 jsp에서 불러오는 식으로 작성하였다.
크롤링된 정보 띄우는 jsp
<section class="ftco-section bg-light">
<%
news news_obj = new news();
List<NewsVO> newslist = news_obj.getNews();
%>
<div class="container">
<div class="row justify-content-center pb-5 mb-3">
<div class="col-md-7 heading-section text-center ftco-animate">
<h2>최신 뉴스</h2>
</div>
</div>
<div class="row d-flex">
<%
for (int i = 0; i < 6; i++) {
%>
<div class="col-md-4 d-flex ftco-animate">
<div class="blog-entry align-self-stretch" style="width: auto;">
<!-- 이미지 mkc 수정 -->
<form id="frm" name="frm" method="get" action="blog-single.bgs">
<input type="hidden" id="DesertionNo" name="DesertionNo" value="">
<a href=<%=newslist.get(i).getUrl()%>
onclick=<%=newslist.get(i).getUrl()%>
class="block-20 rounded"
style="height: 200px; background-position: top; background-image: url('<%=newslist.get(i).getImg()%>'); ">
</a>
</form>
<div class="text p-4">
<div class="meta mb-2">
</div>
<h4 class="heading" style="font-size: 15px;">
<a href=<%=newslist.get(i).getUrl()%>><%=newslist.get(i).getTitle()%></a>
</h4>
</div>
</div>
</div>
<%
}
%>
</div>
</div>
</section>
newsDAO
package dao;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import vo.NewsVO;
public class news {
private Connection con;
public news() {
// TODO Auto-generated constructor stub
System.out.println("it me!");
try {
Class.forName("com.mysql.cj.jdbc.Driver");
System.out.println("DRIVER LOADING.....");
con = DriverManager.getConnection("jdbc:mysql://localhost:3306/throwsgg?user=root&password=1234");
System.out.println("Connection success!");
} catch (Exception e) {
e.printStackTrace();
}
}
public List getNews() {
List<NewsVO> newslist = new ArrayList<NewsVO>();
PreparedStatement pstmt = null;
ResultSet rs = null;
String SQL = "select * from news order by num desc limit 6 ;";
System.out.println("SQL : " + SQL);
try {
pstmt = con.prepareStatement(SQL);
rs = pstmt.executeQuery();
while(rs.next()) {
NewsVO news = new NewsVO(rs.getInt(1),rs.getString(2),rs.getString(3),rs.getString(4));
newslist.add(news);
}
} catch (SQLException e) {
e.printStackTrace();
}
return newslist;
}
}
newsVO
package vo;
public class NewsVO {
private int index;
private String title;
private String url;
private String img;
public int getIndex() {
return index;
}
public void setIndex(int index) {
this.index = index;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getImg() {
return img;
}
public void setImg(String img) {
this.img = img;
}
public NewsVO() {
// TODO Auto-generated constructor stub
this(0,null,null,null);
}
public NewsVO(int index , String title, String url, String img) {
setIndex(index);
setTitle(title);
setUrl(url);
setImg(img);
}
}
뉴스 크롤링 파이썬
#크롤링시 필요한 라이브러리 불러오기
from bs4 import BeautifulSoup
import requests
import pymysql
import time
# while True:
search = "유기견"
page = 1
page_num = 0
if page == 1:
page_num =1
elif page == 0:
page_num =1
else:
page_num = page+9*(page-1)
#url 생성
url = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=" + search + "&start=" + str(page_num)
print("생성url: ",url)
# ConnectionError방지
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/100.0.48496.75" }
#html불러오기
original_html = requests.get(url, headers=headers)
html = BeautifulSoup(original_html.text, "html.parser")
# 검색결과
articles = html.select("div.group_news > ul.list_news > li div.news_area > a")
# print(articles)
# 검색된 기사의 갯수
print(len(articles),"개의 기사가 검색됨.")
#뉴스기사 제목 가져오기
news_title = []
for i in articles:
news_title.append(i.attrs['title'])
news_title.reverse()
print("제목 : ")
for i in news_title:
print(i)
articles2 = html.select("div.group_news > ul.list_news > li a.dsc_thumb > img")
print(articles2)
# 검색된 기사의 갯수
print(len(articles2),"개의 기사가 검색됨.")
result = []
for i in articles2:
result.append(i.attrs['src'])
result.reverse()
print("이미지 : ")
for i in result:
print(i)
#뉴스기사 URL 가져오기
news_url = []
for i in articles:
news_url.append(i.attrs['href'])
news_url.reverse()
print("링크 : ")
for i in news_url:
print(i)
# mysql 연동
conn = pymysql.connect(host='localhost', user='root', password='1234', db='throwsgg', charset='utf8')
for i,j,k in zip(news_title,news_url,result):
cur = conn.cursor()
title = i.replace(",","")
sql = "SELECT title FROM news where title = %s"
cur.execute(sql,(title))
rows = cur.fetchall()
print(rows)
print("INSERT INTO news (title, link, img) VALUES ("+title+", "+j+", "+k+");")
sql = "INSERT INTO news (title, link,img) VALUES (%s, %s, %s)"
cur.execute(sql,(i, j, k))
conn.commit()
# time.sleep(600)
# print("wake up")
주석을 풀으면 10분에 한 번씩 계속해서 크롤링을 하는 프로그램이 된다.